I wanted to re-create the latest Deep Q-Learning results on Atari, a huge milestone for AI Research in the past few years.
Apart from the official code in Lua, I found several Python implementations on github, notably this one from OpenAI or this one among many others. Few Python implementations actually run on Atari environments though, and even less actually report benchmarks comparing to published results. I wasn’t able to reproduce or even run some implementations, including the OpenAI DDQN Atari baselines (see github issue).
After fumbling for several days with bad benchmark results on Atari, I remembered that I implemented a version of DQN for a CS294 homework, which actually works. I added DDQN + Dueling + Prioritized Replay and put it in yarlp (Yet Another Reinforcement Learning Package). Then I ran some more benchmarks!
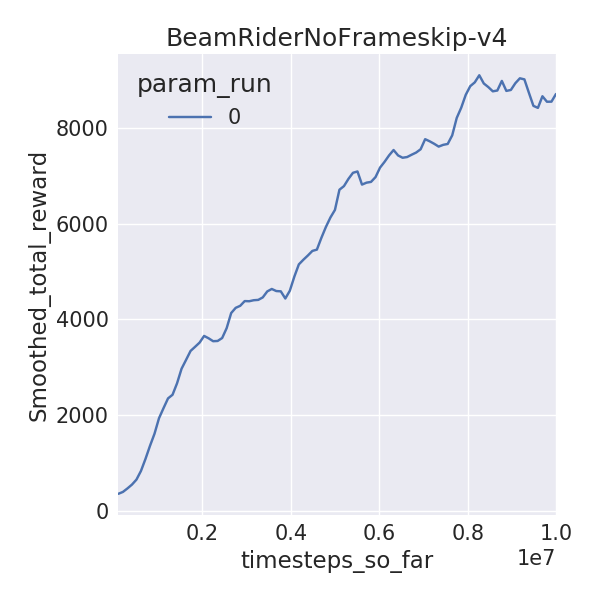
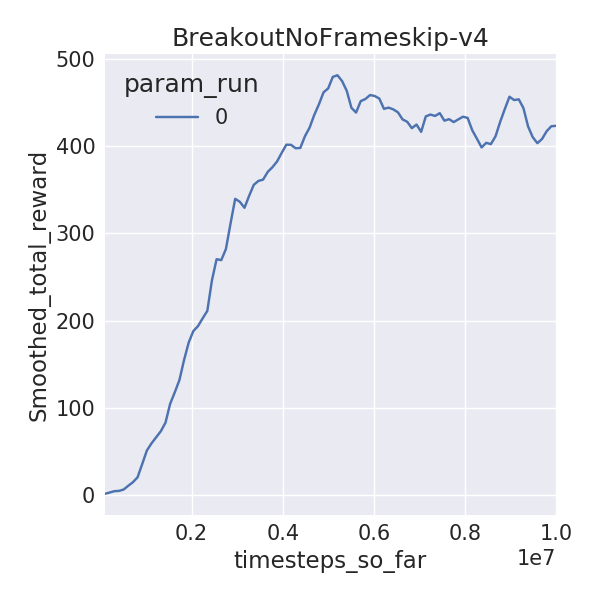
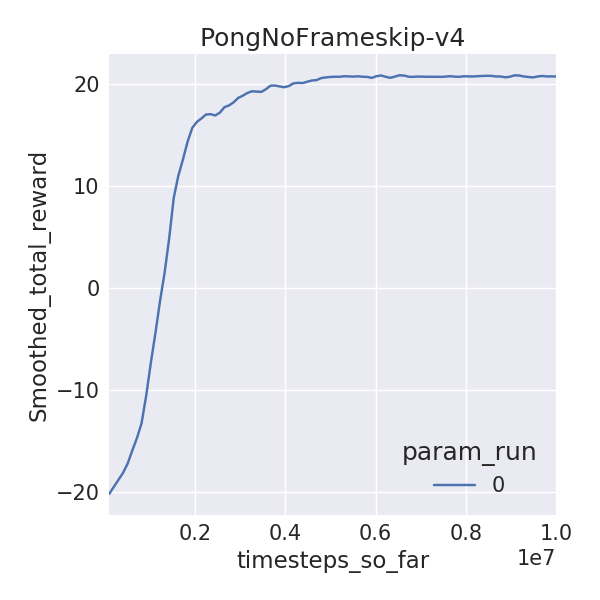
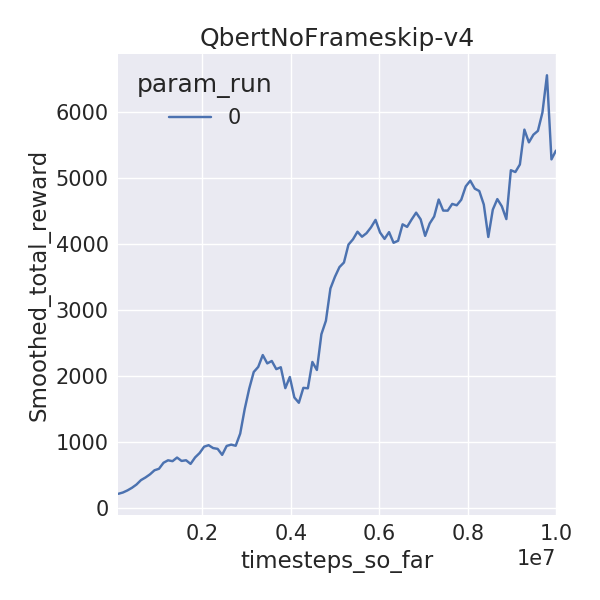
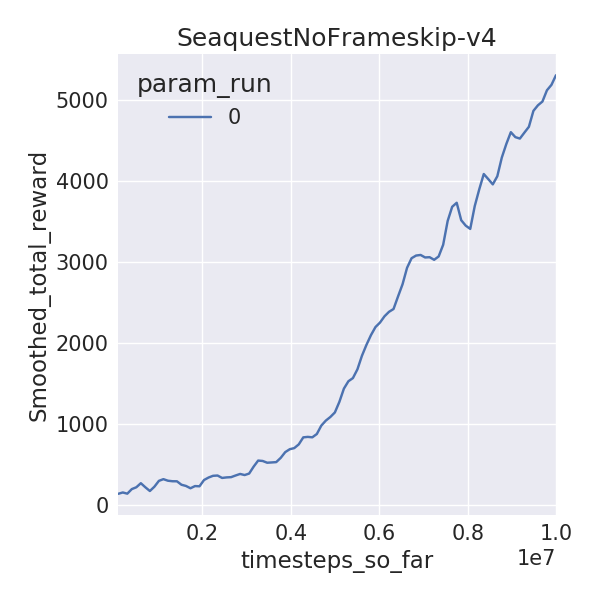
I trained 6 Atari environments for 10M time-steps (40M frames), using 1 random seed, since I have limited time on this Earth. I used DDQN with dueling networks without prioritized replay. I compare the final mean 100 episode raw scores for yarlp (with exploration of 0.01) with results from Hasselt et al, 2015 and Wang et al, 2016 which train for 200M frames and evaluate on 100 episodes (exploration of 0.05). I also compared visually to the learning curves released by OpenAI.
| env | yarlp DUEL 40M Frames | Hasselt et al DDQN 200M Frames | Wang et al DUEL 200M Frames |
|---|---|---|---|
| BeamRider | 8705 | 7654 | 12164 |
| Breakout | 423.5 | 375 | 345 |
| Pong | 20.73 | 21 | 21 |
| QBert | 5410.75 | 14875 | 19220.3 |
| Seaquest | 5300.5 | 7995 | 50245.2 |
| SpaceInvaders | 1978.2 | 3154.6 | 6427.3 |
Here are the learning curves:
 |
 |
 |
 |
 |
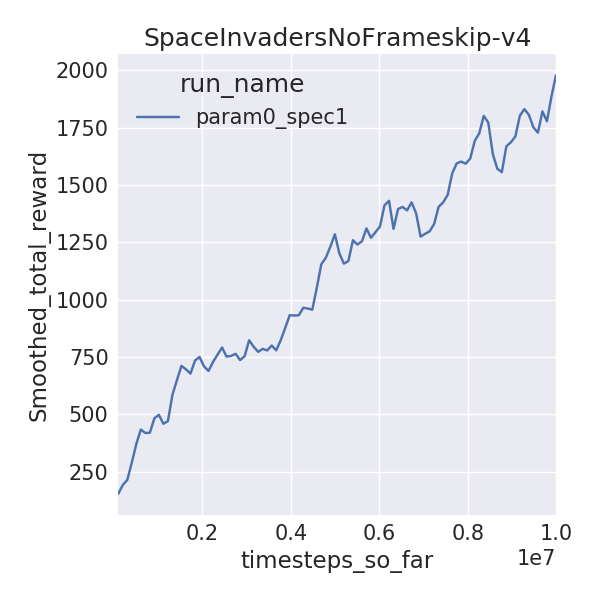 |
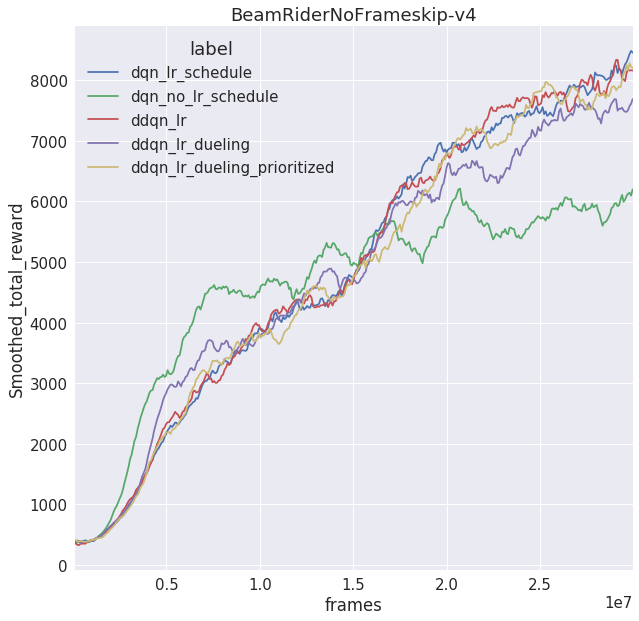
Since I ran for 1/5th of the frames, I wasn’t expecting the final rewards to be close to that of the published results. But some environments are, especially the easier ones like Pong and Breakout. A notable difference between these implementations is that I use piece-wise learning rate and exploration schedules while Hasselt and Wang use linear ones. I wanted to do a mini-ablation experiment to see how these differences stack up against learned rewards. Surprisingly, the piece-wise schedules (lr_schedule vs no_lr_schedule) seemed to make the biggest gain as opposed to dueling networks or prioritized replay! Granted, I didn’t run for multiple random seeds or environments or more frames, but this begs the question, can better exploration and learning rate schedules beat recent advances due to prioritized replay or dueling networks on Atari?
Enjoy some gifs instead!
 |
 |
 |
 |
 |
 |
This blog post pretty much sums up my experience with Deep RL algorithms so far.