There are a lot of RL packages out there, tensorforce, rllab, openai-lab, baselines, and the list goes on. It’s hard to know however, how any of those implementations stack up to published state-of-the-art results. There are several reasons, some are:
- The standard RL tasks (Mujoco & Atari) are extremely sensitive to not only model hyper-parameters but even random seeds (Islam et al).
- Even researchers implementing the same algorithm in two different code-bases have failed to produce consistent results given the same model parameters (described in Henderson et al, e.g. Figure 6).
- It takes time to build reproducible experimentation code.
I’ve been building yarlp for educational purposes, and I wanted to make sure my implementations matched baselines. OpenAI seems to have created something akin to tensorflow models in terms of reproducibility for RL, so a natural step was to benchmark against OpenAI baselines. Nevertheless, I found it quite difficult to match their results because of:
- environment wrappers and how environment observations were normalized
- simple tweaks to model hyper-parameters
- the choice of baseline model
- and random seeds!
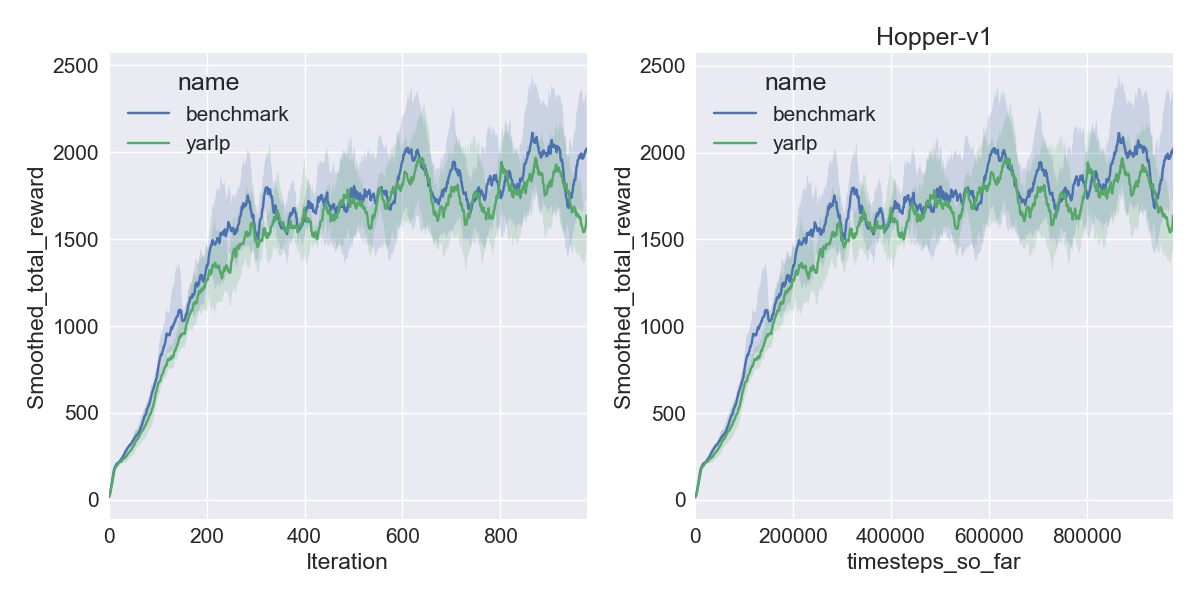
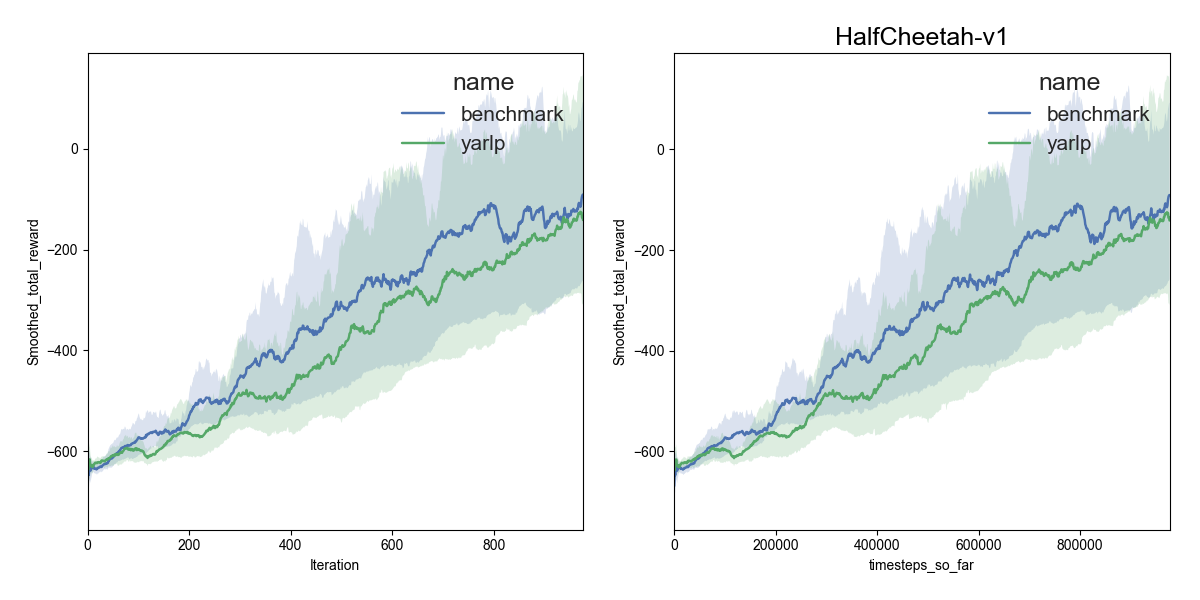
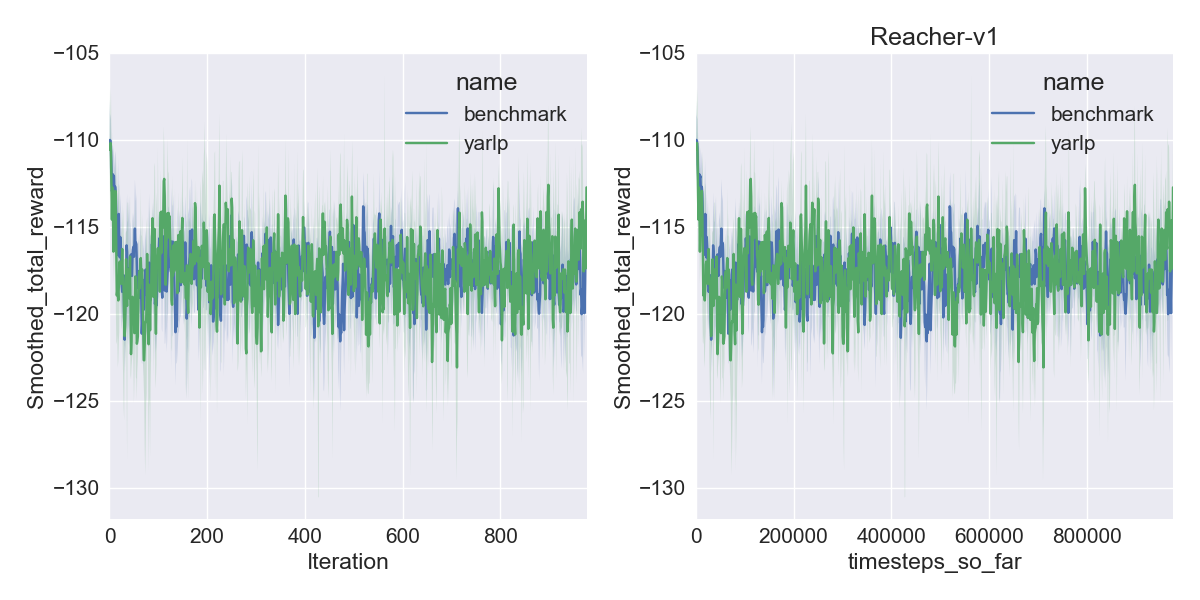
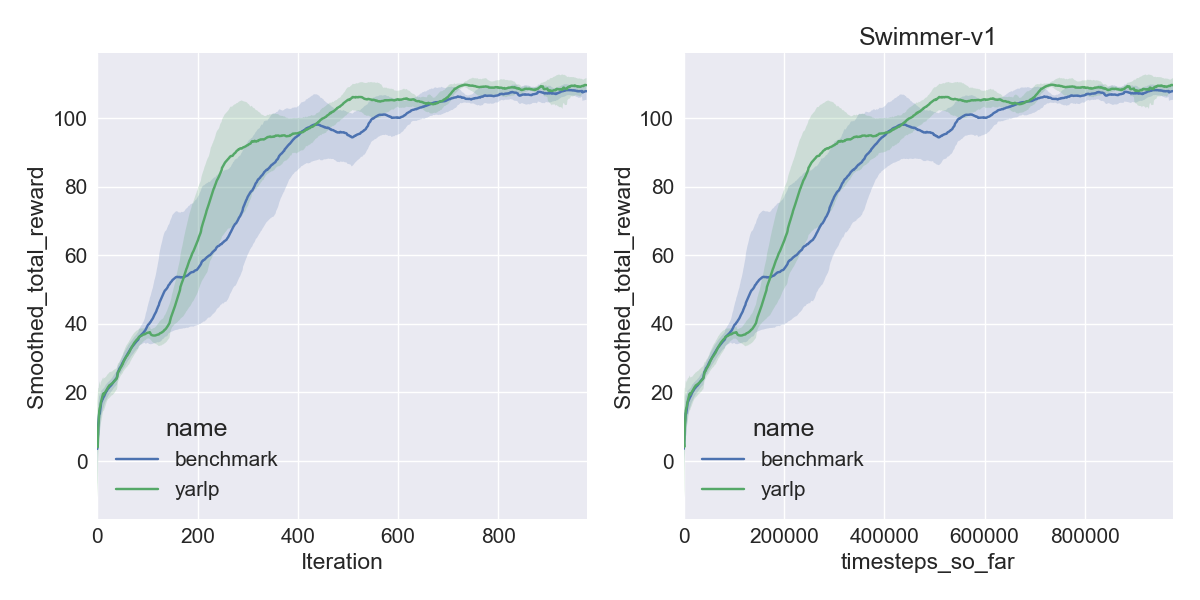
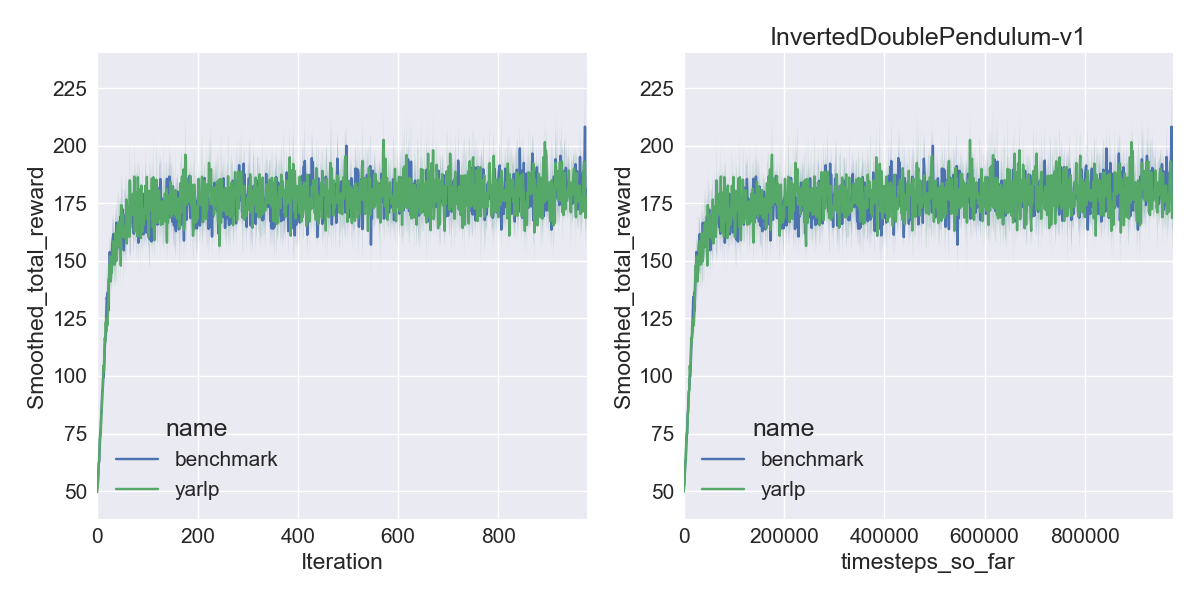
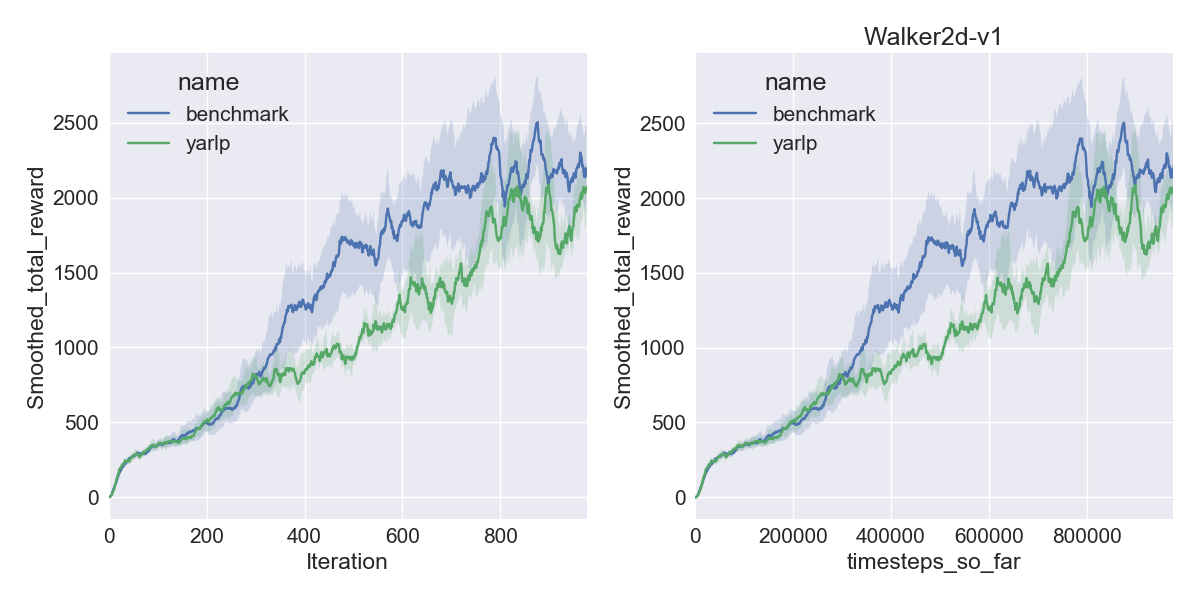
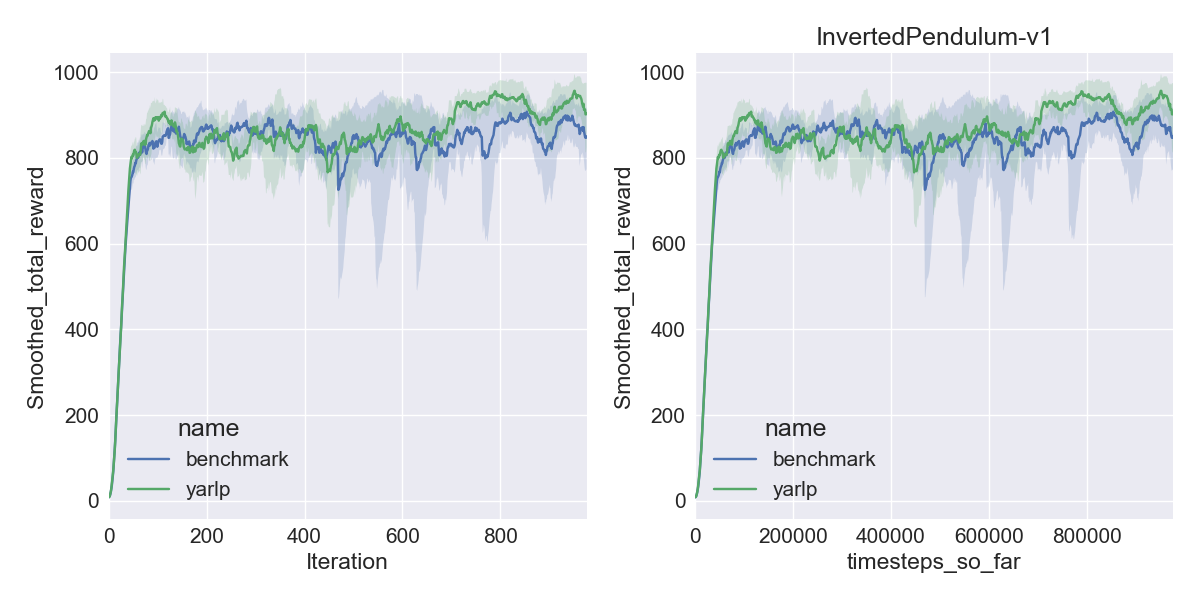
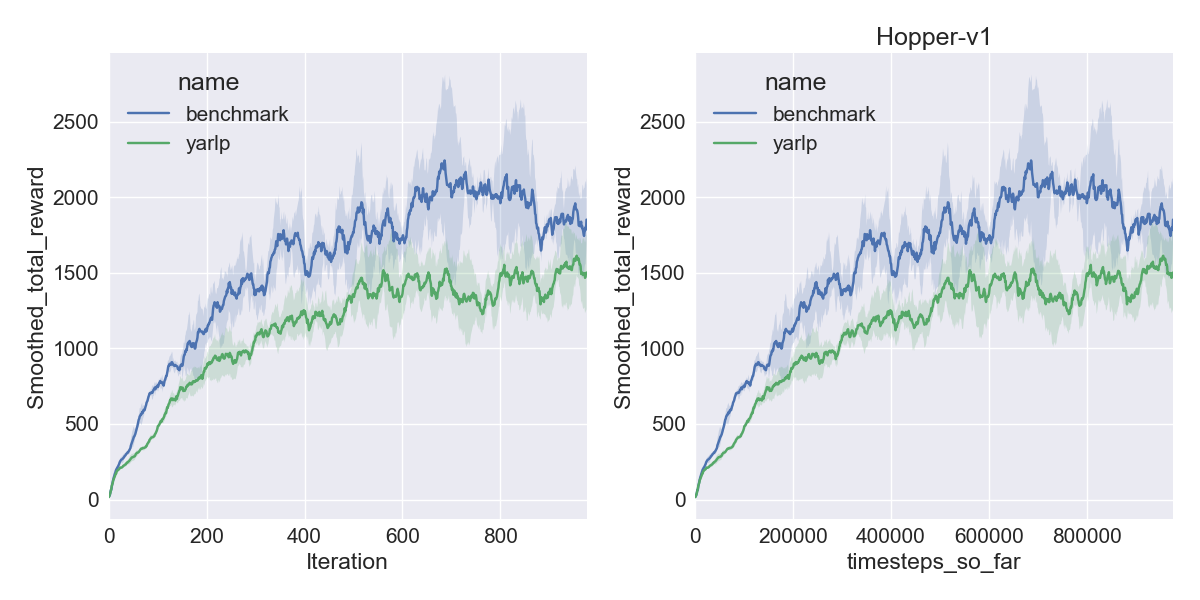
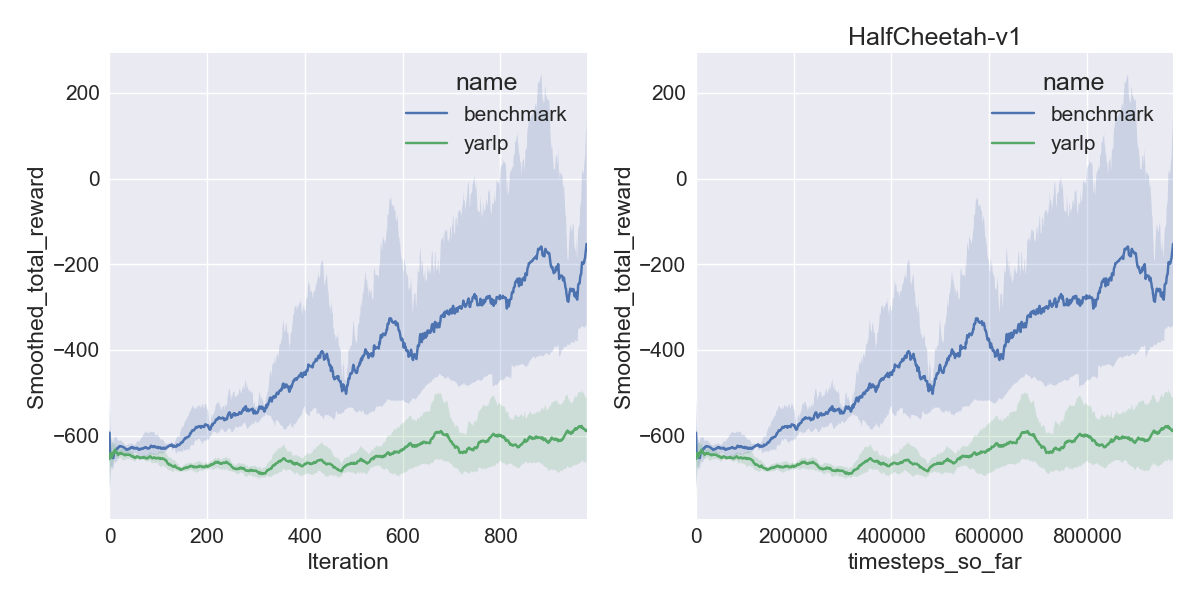
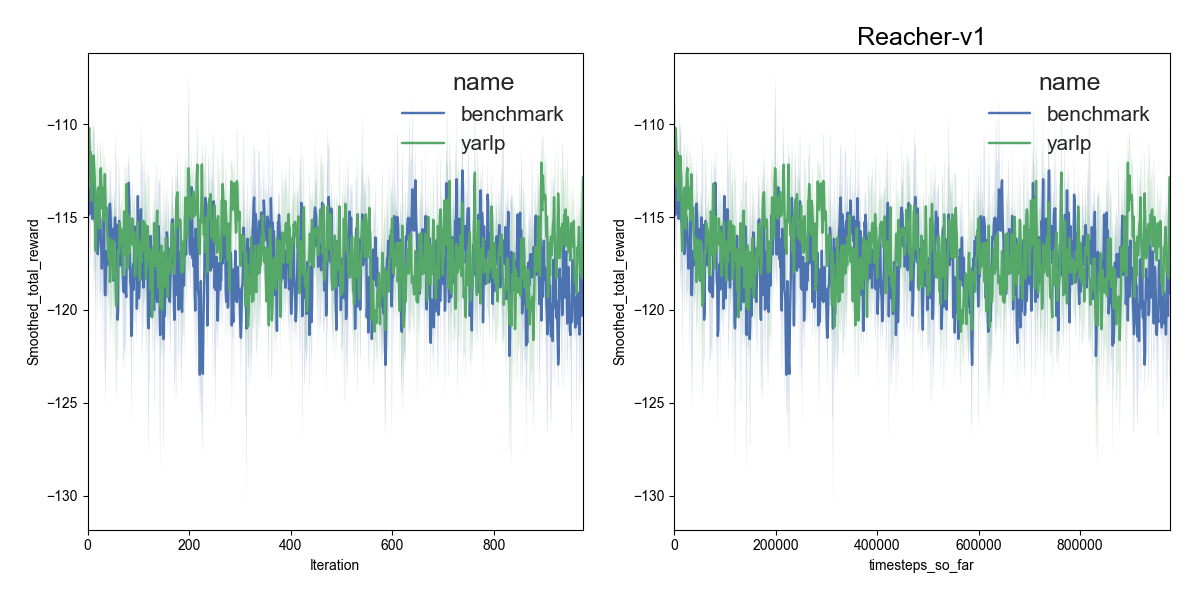
Here are my results on Mujoco1M after painstakingly hashing out minor differences in OpenAI’s implementation of TRPO compared to mine. I averaged over 5 random seeds using this script in baselines, and using the run_benchmark cli script in yarlp, which run all environments in parallel. The results match, but clearly even 5 random seeds is not enough (we plot the 95th percentile CI).
 |
 |
 |
 |
 |
 |
 |
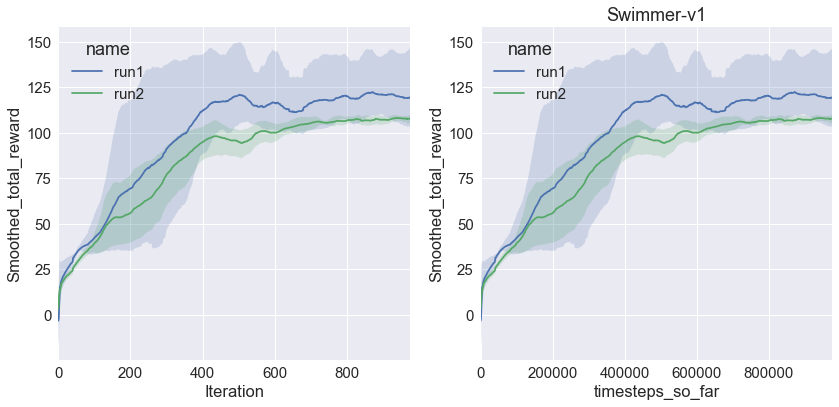
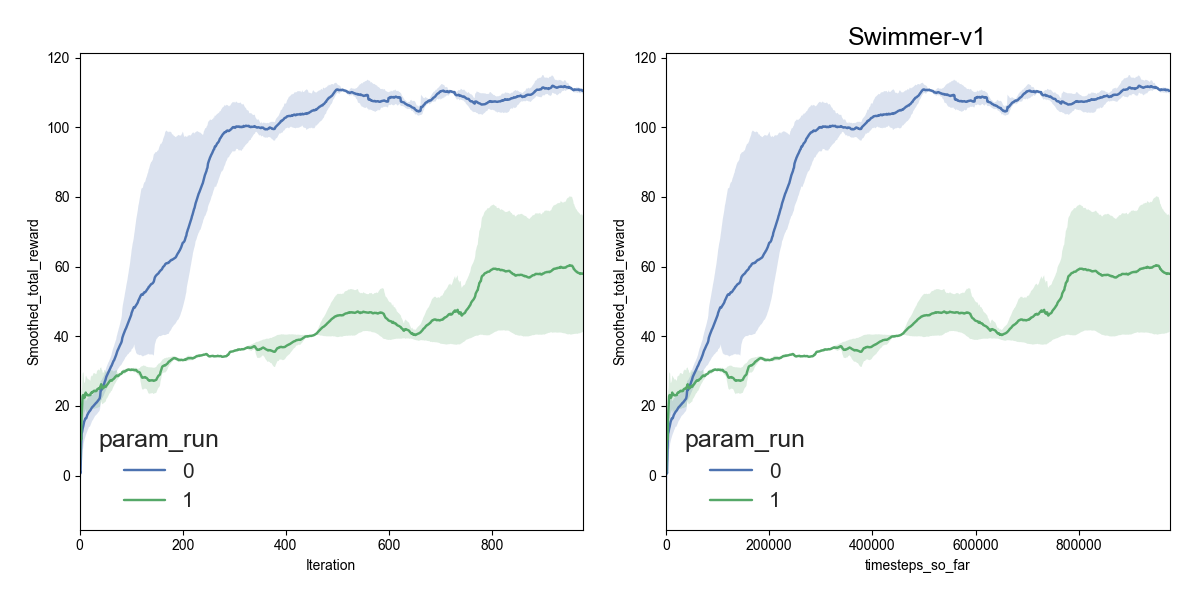
To demonstrate some of the difficulty in reproducibility, here is the same exact algorithm averaged over 2 randomly chosen sets of 3 random seeds on Swimmer-v1 (similar to Figure 10 in Henderson et al):
 |
|
And this is what happens when I use a value function implementation from rllab compared to the one used in OpenAI baselines on Swimmer-v1 averaged over 3 random seeds:
And this is what happens when observations are not normalized on the Mujoco1M benchmark (Walker2d and HalfCheetah perform noticeably worse):
 |
 |
 |
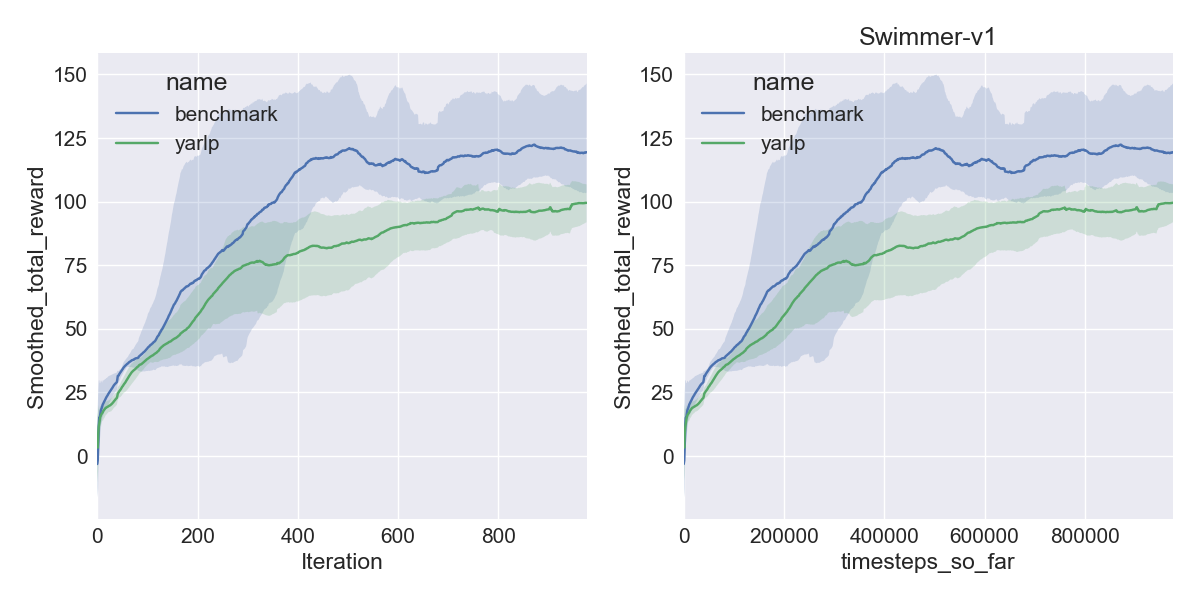 |
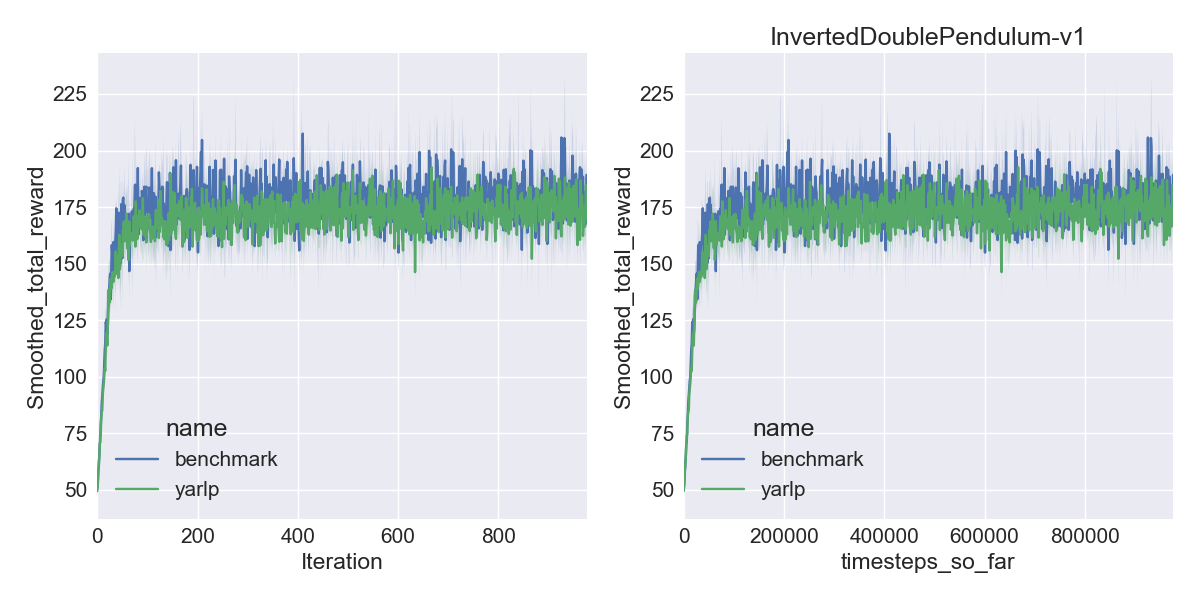 |
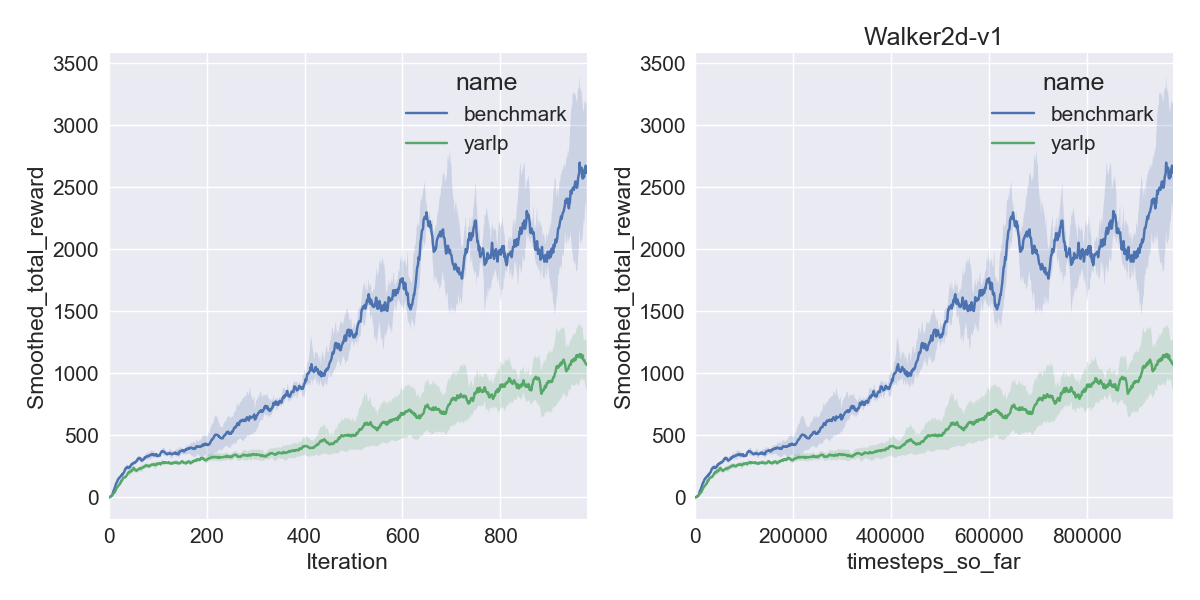 |
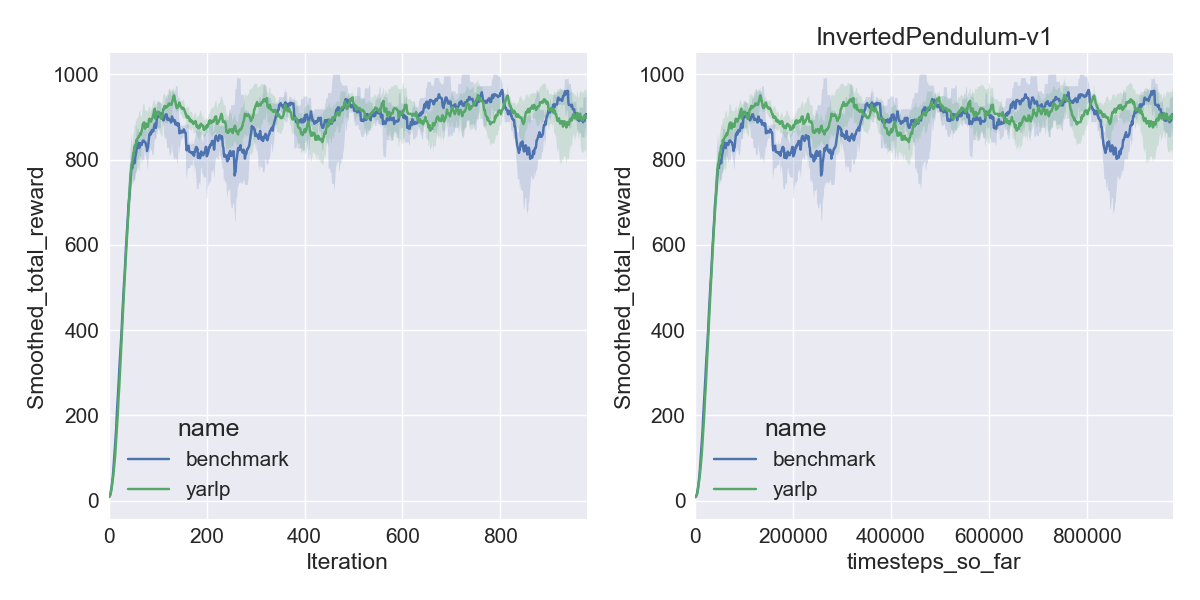 |
One can easily produce these kinds of results for other environments, as seen in Henderson et al.
RL is fun, but it’s a bit concerning how unstable these algorithms and environments can be.